
Mrs Helen Harper, of Jamaica, New York, had an unusual ability — she could play the human voice with her fingers.
It was 1939, and the world’s first electronic speech synthesiser had just been invented at Bell Laboratories in New Jersey. The Voder, as it was named, consisted of a keyboard connected via a bunch of circuitry to a loudspeaker. Under the nimble fingers of Mrs Harper, the Voder spoke and sang to audiences at performances around the country.
A contemporary video of the Voder in action. It has a somewhat metallic voice, but is easily understandable; and Mrs Harper is able to use expression to convey different nuances with the same words.
Two centuries earlier, inventors had already created mechanical speaking devices that modelled our mouth, vocal cords, and lungs. We saw one of these, the Euphonia, in a previous post. But the Voder was unique in being the first machine to speak by electronic means — the precursor to the modern computer-generated voices that are so ubiquitous today. In this post I’ll explain how the Voder spoke, with the help of some demos which imitate its workings.
The Voder’s Sound Source
Just how could a bunch of electrical circuits produce the sound of human speech? To understand this, let’s first briefly recap what we saw in a previous post about how the human voice works. When we speak, air flows from our lungs up through our throat and between our vocal cords. The vocal cords vibrate, opening and closing hundreds of times per second, and allowing the air to escape in pulses.
To mimic this source of sound electronically, we need to know how the air pulses are shaped. Here’s a graph of what the airflow through our vocal cords looks like over two open-and-close cycles:
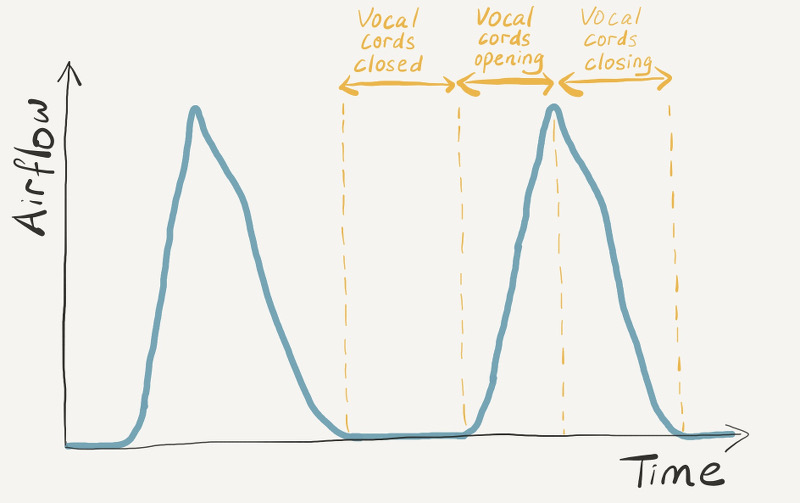
The Voder simulated this source of sound by generating an electrical wave of a similar shape. The wave sounds something like this:
This is what our vocal cords would sound like, too, if we heard them by themselves. But as we saw in an earlier post, this sound gets filtered by the vocal tract (our oral and nasal cavities). The vocal tract picks out certain frequencies and suppresses others, forming mounds in the spectrum called formants. These formants are responsible in part for the differences in tone quality between male and female voices, and also between individual speakers.
But formants play another important role — they allow us to distinguish between different speech sounds. By shaping our mouth differently, we can change its resonant frequencies and shift the formants around, thus producing different vowels.
The Voder’s Electronic “Mouth”
But what about the Voder? It didn’t have a squishy cavity made of muscle which it could shape to modify its sound — it was just a bunch of electronics! Instead, it created formants using electrical circuits called band-pass filters. Each filter picked out a certain band of frequencies, and suppressed others. There were 10 filters in total, each one connected to a key on the keyboard1.
To better illustrate this, I’ve made a few demos that show how we can take the buzzing source sound we heard earlier, and change it into various vowels by picking out only certain bands of frequencies. Let’s take a look at the spectrum of the buzzing sound to see what frequencies are present in it:
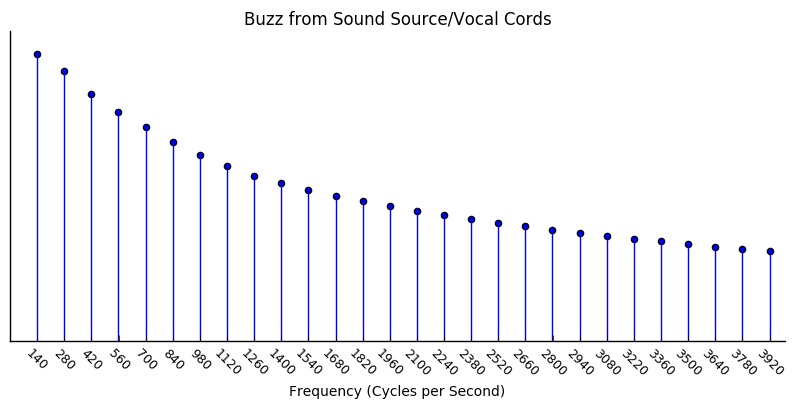
This particular example wave has a frequency of 140 Hz, which means that, had it been produced by vocal cords, the cords would have had to do their open-close cycle 140 times per second. From the spectrum, we can see that the sound also contains harmonics at 280 Hz, 420 Hz, 560 Hz and so on — multiples of the fundamental frequency of 140 Hz.
Click to Expand: A Sawtooth-Shaped Airflow If you look at the graph of the airflow through our vocal cords that I showed earlier, you’ll notice that it looks pretty triangular, instead of being smooth. This is quite important. As we saw in this article about the Fourier theorem, waveforms with sharp corners tend to have lots of strong high harmonics. We’re going to apply band-pass filters that pick out bands of frequencies, corresponding to the resonant frequencies of the vocal tract, and some of these resonant frequencies are pretty high. In order to pick out these frequencies from the source sound, there has to be something there to pick out in the first place! If the source sound were nice and smooth with barely-existent high harmonics, there wouldn’t be very much for the filters to act on.
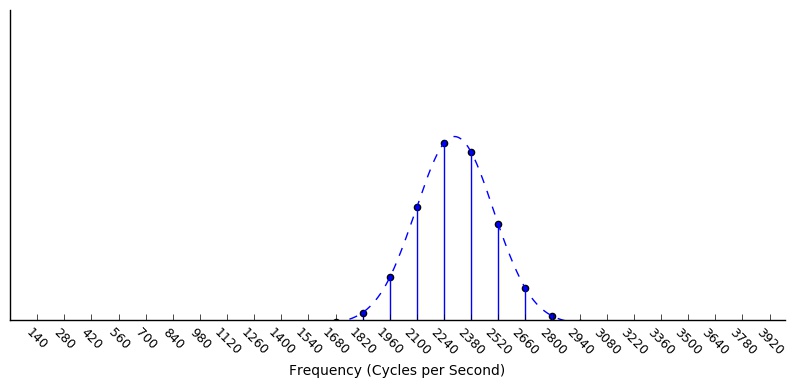
What happens if we take our buzzing sound, and apply a band-pass filter that picks out frequencies near, say, 2300 Hz? We get a spectrum that looks like this:
It turns out that, to make vowels, we need to apply two or three band-pass filters at once. Let’s apply filters at 270, 2300 and 3200 Hz:
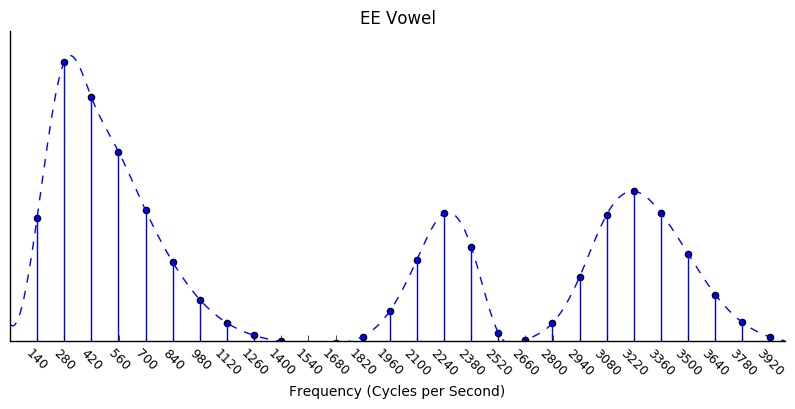
Here, I’ve been a bit fancy with the filters, and adjusted each of their heights, widths and shapes separately. (The Voder probably didn’t have this level of control.) What does this filtered sound sound like?
That sounds like an “ee”. A bit metallic, perhaps, but it certainly sounds more like an “ee” than the original buzzing sound. If we move the three filters around, we can get different vowel sounds. You can hear this in the following video (it has a different fundamental frequency, but the concept is the same):
I don’t know about you, but I find that pretty exciting.
Of course, vowels aren’t the whole story — to pronounce words, we need to make consonants, as well. We produce these by constricting some part of the vocal tract to restrict the air flow. To make different consonants, we can change the place where the constriction occurs, whether or not we vibrate our vocal cords, or the length of the sound.
Let’s take a closer look at these three factors, starting with the last one. Sounds like “s” and “zh” can be arbitrarily long, while sounds like “t” and “b” are short. The latter are called stops, because we produce them by actually stopping the airflow for a fraction of a second, and then releasing a burst of air. We can simulate a stop using a burst of high-frequency sound, and the Voder had special keys to do so.
Consonants can also be voiced or unvoiced. In voiced sounds, the vocal cords vibrate, while in unvoiced sounds, we hold the vocal cords open and let air pass through unhindered. (If you put your finger on your throat while pronouncing the sounds “z” and “s”, you’ll feel the difference.) The Voder’s wrist bar allowed the operator to switch between a buzzing source to produce voiced sounds, and a white-noise source to produce unvoiced sounds, as you heard in the video at the beginning of this post.
What about where we constrict the vocal tract? Compare the sounds “s” and “sh” — in the former, the air passes between the top of the tongue and the roof of the mouth. In the latter, you curl your tongue up a bit, and let the air pass under it. Just like with vowels, the different mouth shapes give the two sounds different formant frequencies, as you can see in the following video.
Now let’s put the consonants and vowels together to say “she saw me”:
That sounds rather flat and robotic… To make the voice more expressive, we can continuously change the pitch of the voice by changing the fundamental frequency of the voiced buzzing source. (The Voder’s operator did this using a foot pedal.) By putting the stress on different words, we can change the emphasis of the sentence:
This demo I made doesn’t sound as good as the original Voder — I think it sounds creepier. It also has particular difficulty with the “m” in “me”, and the expression is perhaps somewhat exaggerated. Evidently, the Voder’s formant filters were very well-tuned — its inventor, Homer Dudley, had previously spent time analysing the human voice using the Vocoder, another machine that he had developed.
Learning to Play the Human Voice
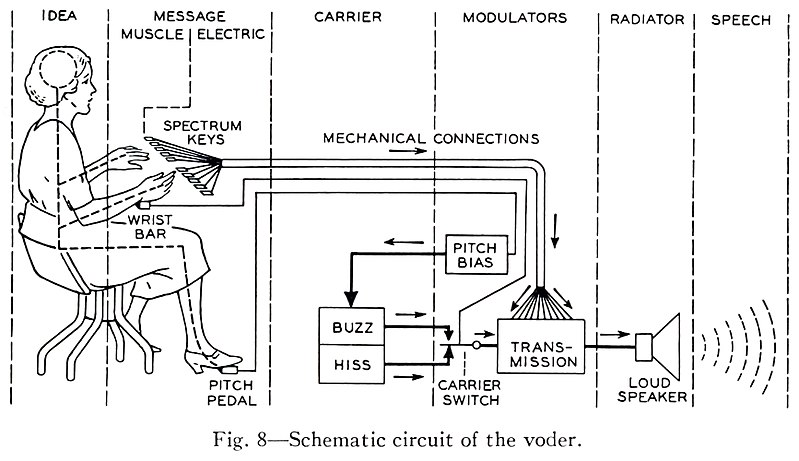
Not only did the Voder’s electronics have to be tuned to perfection — it had to be played to perfection, as well. The operator had to memorise the formant frequencies for each sound, and press the correct combination of keys, pushing each one down just the correct amount — all at the rate of normal speech! She also had to produce the stop sounds, and deal with the wrist bar and foot pedal. As Mrs Harper explained:
“In producing the word ‘concentration’ on the Voder, I have to form thirteen different sounds in succession, make five up-and-down movements of the wrist bar, and vary the position of the foot pedal from three to five times according to what expression I want the Voder to give the word. And of course, all this must be done with exactly correct timing.”
When Stanley Watkins, who programmed the Voder, first sat down at the instrument, he attempted to make it say “yes”. Everyone else present thought it had said “peanuts”. To find someone who would be able to learn to play it well, he searched among the Bell Telephone Company’s telephone “girls”, finally selecting Mrs Harper based on her finger agility, ability to distinguish sounds, and appearance(!)2. She later helped to train a number of other women to operate the Voder; of the 300 women that the Bell Telephone Company tried out, only 28 got good at it3. It took each of them about a year of constant practice to be able to produce intelligible, natural-sounding speech on the machine.
From the Voder to Siri
The Voder was not destined to become a staple of live entertainment, and does not seem to have appeared much after its crowd-pleasing performances at the New York and San Francisco World’s Fairs in 1939 and 1940. However, it marked an important step in the development of artificially-produced speech. Some modern speech synthesisers still use the same basic principles as the Voder — filtering and manipulating a generated source wave — but with computers instead of physical circuits.
The advent of computers meant that written text could be directly converted to speech, without the need for a highly-trained operator playing on a keyboard. Much more convenient, but a lot less fun, wouldn’t you say?
If you’d like to try your hand at operating the Voder, check out this web application by Griffin Moe.
Leave a Reply
3 Comments on "Meet Siri’s Great-Grandfather, the Voder"
super cool! Thank you for making so understandable what otherwise wouldn’t be!
This website is great! I just read through all your posts, and you’ve covered most of what took me years to figure out myself (I haven’t seen this stuff anywhere else).
Amazing !! Read through all the articles of your site. I wish you had continued writing such fascinating posts.